Image OCR¶
Table of Contents¶
Release Notes¶
Version |
Date |
Notes |
|---|---|---|
1.0.0 |
07/2022 |
Initial Release |
Overview¶
IBM SOAR app for text recognition in images
An App that introduces OCR (Optical Character Recognition) functionality to SOAR, which can parse text from images. Uses Tesseract OCR, an open-source package with python bindings, to parse an image and return each line with an attached confidence metric.
Key Features¶
Parse a picture and return lines with associated average confidence, allowing for automated reading of screenshots and other images
Accepts different languages and can filter based on a minimum confidence score per line
Can parse images from artifacts and attachments (see rules and workflows) or directly using a Base64 string
Requirements¶
This app supports the IBM Security QRadar SOAR Platform and the IBM Security QRadar SOAR for IBM Cloud Pak for Security. This app uses a custom build process on the backend which compiles tesseract and dependant libraries from source; this may lead to longer than average installation. Please keep in mind that this app relies on Tesseract 5.0.1, which is popular open-source OCR. Any limitations found in Tesseract 5.0.1 will similary be present in this app e.g. rotated text cannot be detected if it is shorter than 70 characters.
Integration Server Installation¶
If you are running your own integration server (as opposed to using AppHost), you will need to install Tesseract OCR in your environment. Luckily, Tesseract is popular enough that, more often than not, there are pre-compiled binaries. The pre-compiled packages often come with language packages, but not always. Please see instructions below for installing on your OS, as well as how to add more langauges.
You can also build from source, although note that you will need to also install or compile Leptonica. You can check the Dockerfile for this app for an example of how to build from scratch, but keep in mind that it is likely you will not need to build any of the image libraries (libpng, libjpeg, libtiff, etc.) on your own local machine, as they are either present or available through apt, yum, brew, etc.
If you build from source, you should add languages manually, by downloading .traineddata files and placing them in /usr/local/share/tessdata.
For general installation instructions, see here.
Ubuntu and Debian¶
To add a language, you can run sudo apt install tesseract-ocr-{lang}, where {lang} is one of the language codes that can be found here.
Windows¶
MacOS¶
For MacOS there is a brew formula. There is also a brew formula for extra languages.
SOAR platform¶
The SOAR platform supports two app deployment mechanisms, App Host and integration server.
If deploying to a SOAR platform with an App Host, the requirements are:
SOAR platform >=
43.1.49.The app is in a container-based format (available from the AppExchange as a
zipfile).
If deploying to a SOAR platform with an integration server, the requirements are:
SOAR platform >=
43.1.49.The app is in the older integration format (available from the AppExchange as a
zipfile which contains atar.gzfile).Integration server is running
resilient-circuits>=45.0.0.If using an API key account, make sure the account provides the following minimum permissions:
Name
Permissions
Incidents
Read
Org Data
Read
Function
Read
The following SOAR platform guides provide additional information:
App Host Deployment Guide: provides installation, configuration, and troubleshooting information, including proxy server settings.
Integration Server Guide: provides installation, configuration, and troubleshooting information, including proxy server settings.
System Administrator Guide: provides the procedure to install, configure and deploy apps.
The above guides are available on the IBM Documentation website at ibm.biz/soar-docs. On this web page, select your SOAR platform version. On the follow-on page, you can find the App Host Deployment Guide or Integration Server Guide by expanding Apps in the Table of Contents pane. The System Administrator Guide is available by expanding System Administrator.
Cloud Pak for Security¶
If you are deploying to IBM Cloud Pak for Security, the requirements are:
IBM Cloud Pak for Security >= 1.9
Cloud Pak is configured with an App Host.
The app is in a container-based format (available from the AppExchange as a
zipfile).
The following Cloud Pak guides provide additional information:
App Host Deployment Guide: provides installation, configuration, and troubleshooting information, including proxy server settings. From the Table of Contents, select Case Management and Orchestration & Automation > Orchestration and Automation Apps.
System Administrator Guide: provides information to install, configure, and deploy apps. From the IBM Cloud Pak for Security IBM Documentation table of contents, select Case Management and Orchestration & Automation > System administrator.
These guides are available on the IBM Documentation website at ibm.biz/cp4s-docs. From this web page, select your IBM Cloud Pak for Security version. From the version-specific IBM Documentation page, select Case Management and Orchestration & Automation.
Proxy Server¶
The app does support a proxy server.
Python Environment¶
Both Python 3.6 and 3.9 are supported
Additional package dependencies may exist for each of these packages:
opencv-python-headless ~= 4.5.5.64
resilient-circuits >= 45.0.0
numpy >= 1.19
pandas >= 1.1.5
pytesseract == 0.3.8
Endpoint Developed With¶
This app has been implemented using:
Product Name |
Product Version |
API URL |
API Version |
|---|---|---|---|
Tesseract OCR |
5.0.1 |
None |
None |
Installation¶
Install¶
To install or uninstall an App or Integration on the SOAR platform, see the documentation at ibm.biz/soar-docs.
To install or uninstall an App on IBM Cloud Pak for Security, see the documentation at ibm.biz/cp4s-docs and follow the instructions above to navigate to Orchestration and Automation.
Function - OCR: Read Text From Image Bytes¶
runs OCR on an image in byte string format and returns the relevant results
Inputs:
Name |
Type |
Required |
Example |
Tooltip |
|---|---|---|---|---|
|
|
Yes |
|
incident id, typically incident.id |
|
|
No |
|
used for file-based artifacts, typically artifact.id |
|
|
No |
|
attachment id, typically attachment.id |
|
|
No |
|
used with task level attachments, typically task.id |
|
|
No |
|
When running the function without an artifact or attachment, it is possible to supply an image in base64 format, using inputs.ocr_base64 |
|
|
Yes |
|
This is the minimum confidence considered before returning a line. Confidence of a line is the average confidence across all words in a line. This value defaults to 50, which means the app will return any line with an average confidence of 50% or more. We recommend a value greater than 80 for sensible results |
|
|
Yes |
|
This determines what language Tesseract will look for i.e. if the text is in arabic, we would specify ‘ara’. See next toggle heading for a table of languages and their corresponding code. This can always be checked here, and the Dockerfile contains steps on how to install your own language |
Language Codes:
Language |
Language Code |
Info |
|---|---|---|
English |
|
Default in SOAR |
Arabic |
|
|
Spanish |
|
|
Chinese Simplified |
|
Can also be read vertically |
Chinese Traditional |
|
Can also be read vertically |
French |
|
|
German |
|
|
Korean |
|
Can also be read vertically |
Japanese |
|
Can also be read vertically |
Outputs:
NOTE: This example might be in JSON format, but
resultsis a Python Dictionary on the SOAR platform.
results = {
"content": [
{
"confidence": 93.921173,
"text": "Description"
}
],
"inputs": {
"ocr_artifact_id": 23,
"ocr_base64": null,
"ocr_confidence_threshold": 49,
"ocr_incident_id": 2098,
"ocr_language": "eng",
"ocr_task_id": null
},
"metrics": {
"execution_time_ms": 1161,
"host": "Host",
"package": "fn-ocr",
"package_version": "1.0.1",
"timestamp": "2022-06-27 14:08:28",
"version": "1.0"
},
"raw": null,
"reason": null,
"success": true,
"version": 2.0
}
Example Pre-Process Script:
inputs.ocr_incident_id = incident.id
inputs.ocr_attachment_id = attachment.id if attachment.id else None
inputs.ocr_task_id = task.id if task and task.id else None
inputs.ocr_confidence_threshold = rule.properties.ocr_confidence_threshold
inputs.ocr_language = rule.properties.ocr_language
inputs.ocr_base64 = None
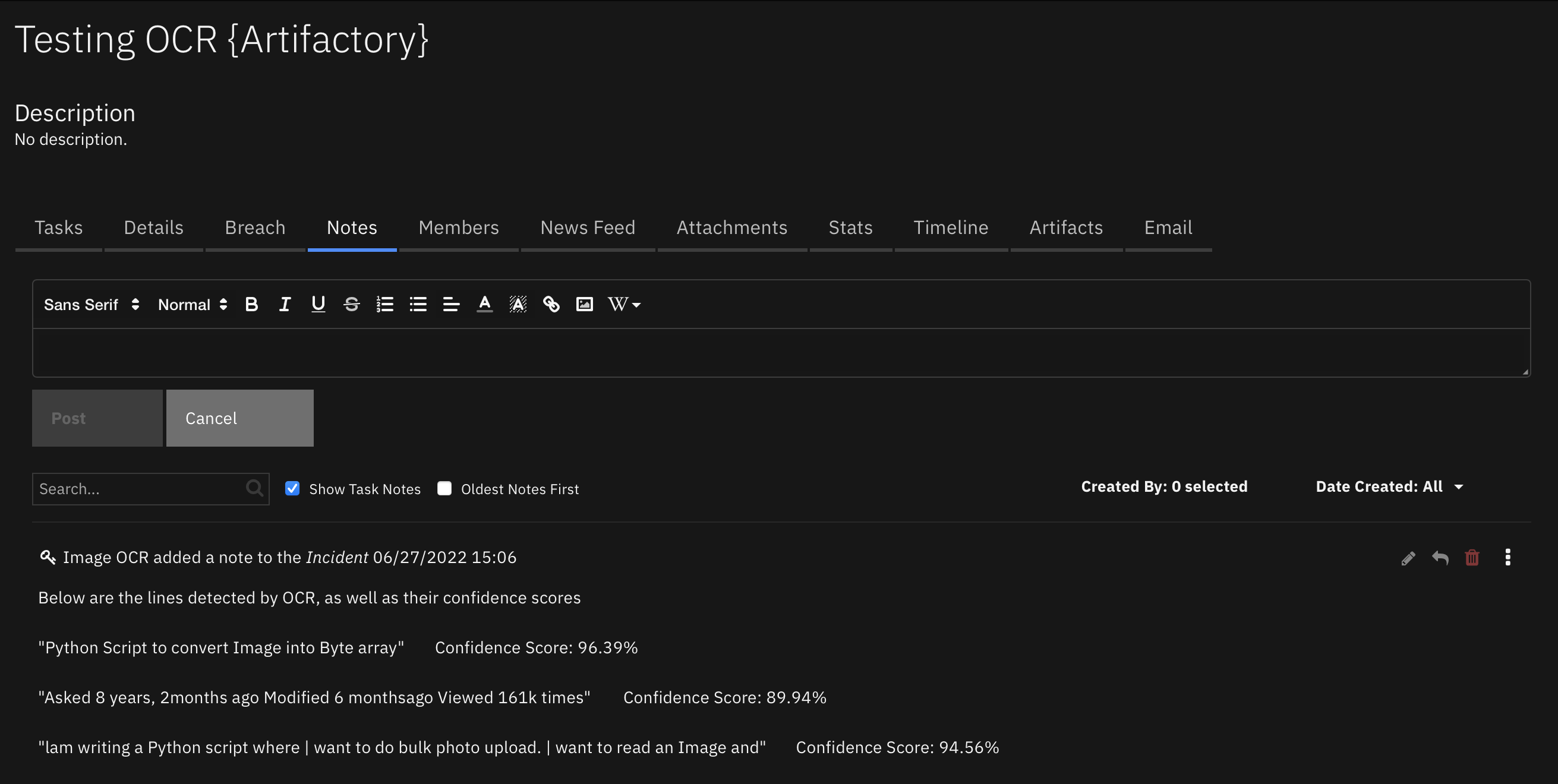
Example Post-Process Script:
content = workflow.properties.ocr_results["content"]
if content is not None:
output_text = "Below are the lines detected by OCR, as well as their confidence scores (threshold = {0})\n\n".format(workflow.properties.ocr_results.get("inputs", {}).get("ocr_confidence_threshold"))
for line in content:
output_text += '"' + line.get("text",None) + f'" \t\t <i>Confidence Score: {round(line.get("confidence", None),2)}%</i>\n\n'
incident.addNote(output_text)
Rules¶
Rule Name |
Object |
Workflow Triggered |
|---|---|---|
Parse Image (Artifact) |
artifact |
|
Parse Image (Attachment) |
attachment |
|
Parse Image (Base64) |
incident |
|
Troubleshooting & Support¶
Refer to the documentation listed in the Requirements section for troubleshooting information.
For Support¶
This is a IBM Community provided App. Please search the Community ibm.biz/soarcommunity for assistance.